I've been reading up and playing with Microsoft Azure SQL DW offering. What follow are some consideration you might want to take advantage off, when deciding on such an implementation.
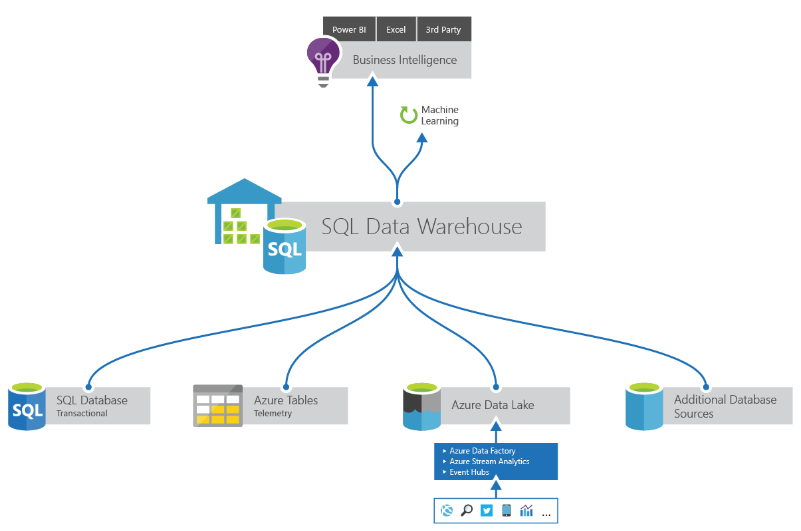
Azure SQL DW, is a fully managed Platform as a Service (PaaS) that empowers us, to design and mange, a fully functional Data Warehouse, while reducing its maintenance burden.
The Platform is based on a Massive Parallel Processing (MPP) system, governed by Distributed Storage and Distributed Compute.
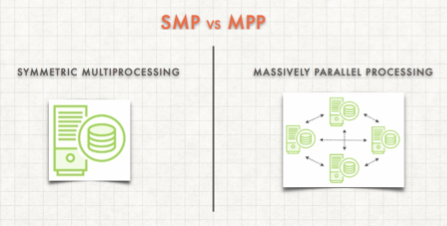
Data Warehousing Unit is a measure of the underlying compute power of the database.

When it comes to Distributed Queries, this is something which gives Azure SQL DW its power and the ability to analyze massive volume of data. When a user submits a query, that query is broken up and distributed across the compute and pushed down against the compute at the storage level to process that result. As the results are calculated, the intermediate values are passed back through to the control node from the storage and given result to the user. That means that there is multiple level of calculation that take place.
In addition to this massive power, with Azure SQL DW what we have is the ability to use Geo-Redundancy to actually maintain an higher level of availability. You can take a Geo-Redundant snapshot off a storage and hosting it on another reagin data center.
Azure SQL DW Design considerations
Data Distribution
Data Distribution is governed by a distribution key that determines the method by which Azure SQL DW spreads the data across nodes.
An Even data Distribution is always preferred and most importantly avoid data Skew.
As of this writing Hash and Round-Robin are the only two disruption type keys provisioned.
Round-Robin guarantees a uniform distribution. It is essentially a random distribution, designed to keep the data nice and even. However, at times it comes at a performance risk.
Hash Distribution (optimized form). We can optimize the distribution by using a technique called Hash distribution. With this type of distribution is good practice to avoid nullable column for distribution.
Good Hash keys share some of the following attributes.
- Distributes Evenly
- Used for Grouping
- Used as Join Condition
- Is not Updated
- Has more than 60 distance values
Azure SQL DW uses up to 60 distributions when loading data into the system.
Data Types
Data Type considerations is needed. However, the goal here is not only to save space, but to move data as efficiently as possible.
- Use the smallest data type that fits your data.
- Avoid defining all character columns to a large default length.
- Define columns as VARCHAR rather than NVARCHAR if you don’t need Unicode.
Table Types
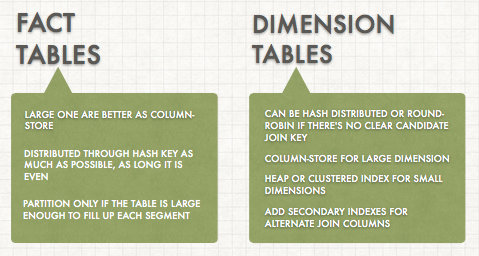
Tables in Azure SQL DW are of the following types.
Cluster Columnstore is the default table type and is meant for large tables. It is organized by column.
- This type of table offers High Compression Ration and it is ideally of 1 Million rows segments.
- No secondary indexes are available.
Heap table are usually used as small temporary tables. No ordering or index is applied to the data.
- Ideal for fast load
- No compression
- Allows secondary indexes
Clustered B-Tree Index A table that is organized on a sorted column that usually becomes the clustering key.
- Stored index on the data
- Fast singleton lookup
- No compression
- Allows secondary indexes
Table Partitioning
Azure SQL DW table partitioning has to be chosen wisely.
Things to consider:
- A highly granular partitioning scheme can work in SQL Server but hurt performance in Azure SQL DW
- Lower granularity (week, month) can perform better depending on how much data you have.
Loding an MPP system
The main principle of loading data into Azure SQL DW is to do as much work in parallel as possible.
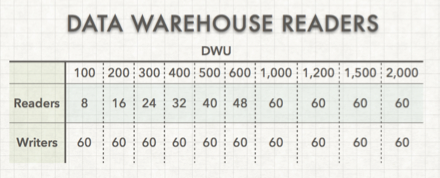
Data Warehouse Units (DWU) have a direct impact on how fast you can load data in parallel.
Optimize Insert Batch size Avoid trickle insert pattern. The ideal batch size is 1 million or more direct on in a file.
Avoid ordered data Data ordered by distribution key can introduce hot spots that slow down the load operation.
Create Table As The best practice approach when moving and transforming data into Azure SQL DW.

User resource Class User resource classes are database roles that govern how many resources are given to a query.
There are four resource classes that a user can belong to in Azure SQL DW.
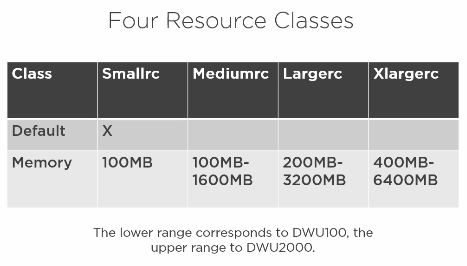
For fast and high quality loads, create a user just for loading, which utilizes a medium or large resource class.

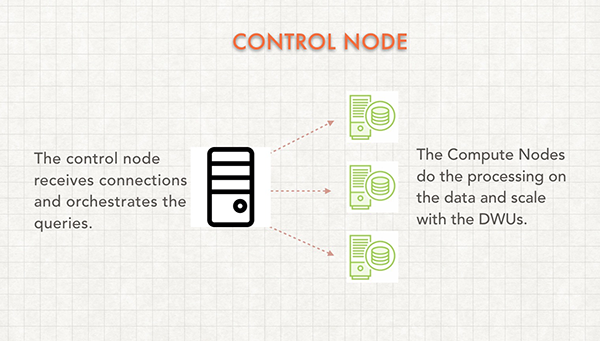
The Control Node will always be the same regardless of how many DWU you add. However, you will get more Compute Nodes as your DWU increases.
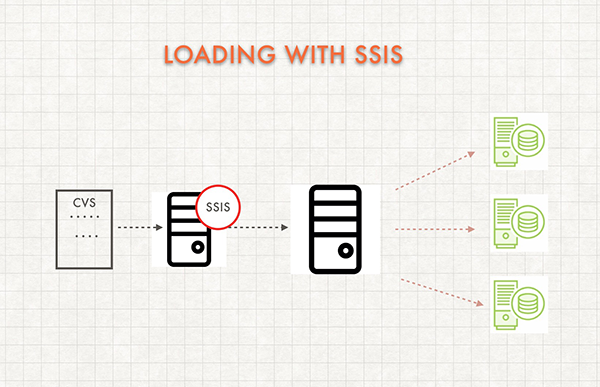
As we can see when loading with SSIS, SQL Server Integration Services, the Control Node becomes the bottleneck. Therefore, we only want to load small amount of data with SSIS.
Loading data with PolyBase is the recommended method to loading large data because it happens in parallel.
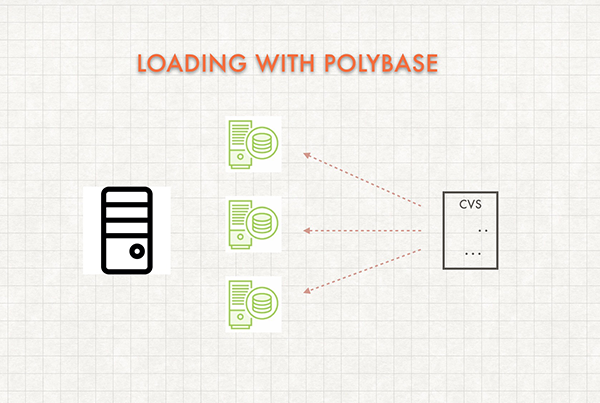
PolyBase can load data from UTF-8 delimited text files and popular Hadoop file formats like RC file, ORC, and Parquet. In addition to, gzip, lib, and Snappy compressed files. However, keep in mind that multiple readers will not work against a compressed file. This is due to the fact that it has to uncompress the file before it can read it

Microsoft Azure Storage Explorer helps you to easily work with Azure Storage from any platform anywhere.
In summary, there are several Best Practice for loading data that can help you get the best loading time. There are two node types, Control and Compute nodes. And there are two types of load methods; single-client and fully parallel with PloyBase. Furthermore, the Azure Data Warehouse migration utility can be used to plan your migration.
There has never been a better time to explore how a cloud-based solution can modernize your business.